
Privacy and Personal Computing in 2018
Posted: 2018-08-19.
This post will walk through how our personal computing devices reveal information about us and what control we have over this process. Privacy and tech can feel overwhelming, but you don't need much technical knowledge to understand these issues!
We'll start by breaking down computing devices and how they communicate over the web, go in more depth regarding web browsing, then talk about ways to control this process.[1]
Computing from 30,000 feet
Let's start basic. It will lay some useful groundwork.
Personal computing devices -- including desktop and laptop computers, tablets, and phones -- can be pictured as three components: hardware, operating system, and programs (nowadays called apps ... you kids ... harumph).
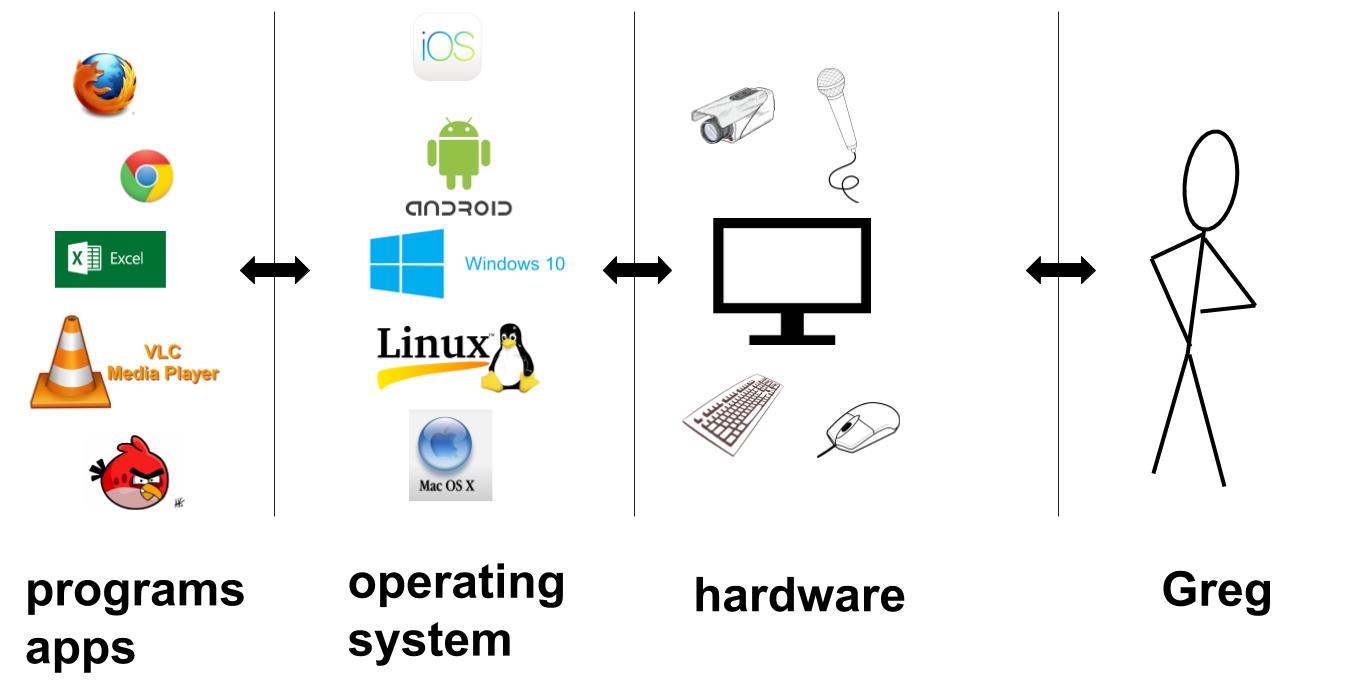
All connections to the outside world go through hardware. Speakers and screens, cameras and microphones; keyboard, mouse, and touch; data via the Internet; and so on. The hardware also includes the CPU, memory, etc: parts that Get Stuff Done when software requests it.
Software, as a working definition, is any kind of programmable, modifiable code stored in memory somewhere on the device. (A program is just a series of instructions telling the hardware what to do: display this, save that, send data to the other.)
The first big category of software is the operating system: Windows, Mac OS X, Linux, iOS, Android, and others. The OS determines what kinds of programs can run and how they interact with the hardware. It manages things like where files are stored and permissions for programs to do things like open files or use the microphone.
The second big category is of course the programs you install and run: web browsers, document writing and editing, photo taking and editing, games, media players, and the list goes on. Recently web browsers have taken over more and more responsibility for these tasks, especially on the desktop.
I don't want to get too philosophical too early, but my view is that if you own the hardware (e.g. phone or laptop), then it should be completely up to you what software it runs. And of course, you choose software that best serves your needs and preferences. Naturally, you wouldn't choose to run software that actively harms you or exploits you for someone else's benefit. Right? We'll see.
![The things you own end up owning you[r data].](images/fightclub-data.jpg)
The Internet from 30,000 miles
What happens when two devices communicate over the Internet?
When Alice types "https://www.duckduckgo.com" into her browser, it first needs to know where to find that website. It sends a message to a service called the domain name servers, which act like a phone book (if you are under 25, get your parents to tell you what a phone book is). These respond with the IP address for that webpage. This is the "address" of the computer that holds the DuckDuckGo homepage. Then, Alice's browser sends out a request to that address.
(If you noticed that knowing the IP address would let you skip the first step, you're right! For example, at the time of this writing, entering the address "45.79.188.27" into your browser bar will take you directly to my homepage; so will "bowaggoner.com", it just takes extra steps.)
The computer located at that IP address receives Alice's request and sends back the webpage. Alice's request included a return address -- the IP address of her own computer.

"Alice's right foot, Esq. 129/55/ block, neighborhood of Boston, (With Alice's love)."
Let's quickly go over webpage encryption, or SSL. This is the "s" in https://. If you connect to a page over plain http, then your messages are unencrypted and any computer in the middle can read them or even modify them. In fact, Internet Service Providers (ISPs) like Comcast have been known to modify the unencrypted webpages you read (at least when net neutrality is unenforced).[2] On encrypted "https" pages, often shown in browsers these days with a "green lock" icon, the exact web address beyond the top-level domain and the contents of the page are encrypted so that only Alice can read them. Her responses are encrypted so that only DuckDuckGo can read those. How this is done is a whole thing we don't need to get into, but partially the answer is: mathematics!
How does this communication physically work? When Alice sends a request to a particular IP address, it first goes from her computer to a router (at home, the library, work, school, etc: the process is the same). This router will look at the IP address and determine which of its neighboring routers to send the message to. It has a rough sense that e.g. IP addresses starting with 1.6 and 1.7 should go to India, for example, so it sends those requests toward neighboring routers in that direction. As the request hops closer, the routers have more specific information about where that IP address is currently located, and within probably a dozen or two dozen hops, it is routed to the correct computer.
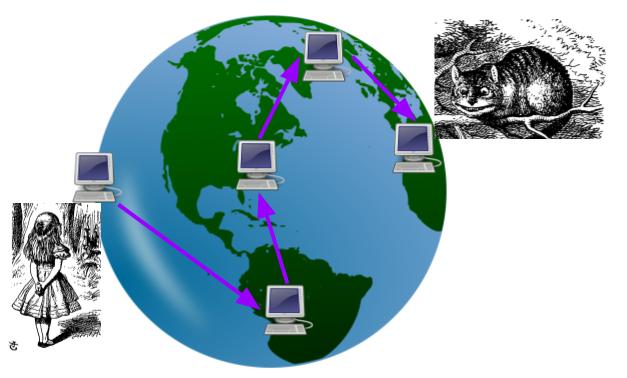
Some important implications: IP addresses generally work like physical addresses. If you move your laptop from home to work, it will have a completely different IP address. But these addresses also change frequently. Alice's ISP may currently have assigned her one IP address, but it is likely to change relatively often, depending on where she is. As these local changes take place, the routers update their knowledge of where different addresses are and how to route packets.
Before leaving orbit, let's discuss Internet service providers. The ISP that you're paying for internet access controls your first router stop, the gateway to the rest of the web. So it sees what sites you connect to. It can block sites completely, slow down some kinds of traffic like video or gaming, or even, as mentioned above, modify your unencrypted webpages. And indeed ISPs have done all of these things, some of the impetus for net neutrality laws.[3] In the USA, since mid-2017 it can legally sell your browsing information to third parties.[4] When you use mobile phone data, the phone company's satellites are your ISP and you route through them. They also can collect and sell information and are known to do so in real time. When you visit a site, its operator can send your IP to e.g. Sprint and get back your real identity: name, address, etc.[5]
Back down to Earth
With that background, let's talk about how devices collect and transmit information about you. Companies say they have good reasons for doing this. I'm not trying to discuss those reasons here; that's between them and you. But I do believe that you have the right to be aware of what happens on your devices and decide what software you want to run.
We'll follow the basics above, starting with hardware. Hardware? Yes, unfortunately, hardware can spy on you. For example, it turns out that many processors are built with a second, miniature, permanent, hidden operating system installed. It can in theory see everything your computer does, access all your data, and send this information anywhere without you knowing.[6] Of course, Intel and AMD say it doesn't, but it has been found vulnerable to hackers.[7] Like other cases, if it stays secure, then it's not a privacy risk, but that's mostly out of your control (though some device or laptop vendors attempt to disable it).
Hardware can also transmit signals conveying information about you. A primary example is the broadband cellular connection on your phone. When on, it is alerting nearby cell towers who you are and your approximate location. Cell phone companies sell this data and it has been leaked in the past.[8] Other objects in our lives increasingly have built-in computers (essentially hardware from our perspective, as we can't modify it) that transmits such data. These include cars (Tesla continuously collects data about its drivers[9], and e.g. Onstar has collected driving habits with intent to sell[10]), so-called "smart" devices like utility meters that collect electricity and water usage data[11], so-called "smart" TVs that collect viewing history[12] or record your conversations[13], and so on.

Next, let's talk about operating systems. Currently, Windows 10 collects data by default about your usage of the system, with justifications as discussed above. (I'm told there are options to turn off some of this tracking.) Of course, proponents of open source and free software would tell you that, since the operating system's source code is proprietary, we really have no idea what it's doing and what data it sends -- only Microsoft's word for it, in this case. Other operating systems also collect information to some extent; some versions of Linux allow opt-in to reporting frequently-used programs.[14] Hardware vendors who sell devices may install tracking software with the OS; Lenovo got in trouble over this.[15]
Finally, there are the main offenders: programs, or if I must, "apps". In general, if you run a program on your computer or phone, there are a lot of nasty things it can do. It might look through your tax documents or photos and send them off somewhere; it might access the camera and take new pictures; it might log the keys that you have been pressing in search of passwords. Running software requires some level of trust.
Now, the operating system controls permissions given to programs, so for example, your phone hopefully does not allow apps to use the microphone or access photos without your explicit permission. These settings might be worth paying attention to, since phone apps e.g. use your microphone to track what TV you watch[16] (though claims that Facebook and Instagram listen to your conversations are apparently currently false[17]). Similarly, web browsers act as miniature operating systems themselves these days (see "sandboxing" below), although they don't always offer fine-grained control over webpages' permissions.
Beyond this explicit permissioning, deciding what programs to run on your computer is mostly a matter of trust. Again, free and open source software by default has a higher level of trust as it can be and usually has been audited for bad behavior.
Trust: a case study
Let's take a break and look at an example: accessing to one of your accounts (say Facebook) with a third-party program, i.e. a program written by neither you nor Facebook. You type your Facebook login and password into that program, and it accesses Facebook for you and retrieves information, etc. on your behalf.
Note that during this process, you gave your Facebook password to the company who wrote that program. Hopefully their app doesn't save the password to a remote server or make it accessible to their employees. Hopefully they don't use it to log into your account without you knowing or download data about you. But you have no way of enforcing any of this, unless the program is open source and you have audited it.
Similarly, remember that you are implicitly trusting every layer of software you run. When you type a password into a web browser and the page is running javascript from many different sources (see below), you are trusting all of them not to spy on your password. Meanwhile the browser itself (like Chrome or Firefox) could also easily be logging that password and sending it somewhere, as far as you know. Similarly, the operating system that browser is running on -- Windows, Android, etc. -- could be doing the same thing. Hopefully it isn't. But just remember: in today's world, running software means trusting the people who wrote it and delivered it.
Okay. Time in.
Web browsing
This is the most important part of this post: how do modern webpages work and collect information about you? (Everything so far was just warmup.)
A webpage is a document in HTML format. This is The Thing that the server sends Alice when her computer requests a webpage. It is really a program (written in plain text -- you can View Page Source in a browser) that tells your browser what to load and how to display it. Here are the main components a page can have (leaving aside media such as videos).
Text and images.
Initially, webpages were mostly or exclusively text, along with some formatting like bold, italics, large, and blinking marquee. The webpage delivered the text and inline images along with some styling instructions, and the browser followed these styling instructions in its own way. In other words, data is delivered to your computer: your browser determines how to display it to you (along with suggestions from the webpage designer). Many pages are still designed in this few-frills way.Even with plain text, the site you're connecting to still learns at least the fact that someone connected, the date and time, and the IP address that connected. This is the idea behind tracking pixels in emails: send an email with a remote image embedded; when the user loads the email, their computer connects to your server to fetch the image and you learn when and where they are reading the email from. Some providers like Gmail block all remote images by default for this reason.
Cookies.
A next step in web design was interaction with the page. A "cookie" is a piece of data that the webpage asks your browser to store in your computer. When you visit a new page, it may ask to see your cookies and use that data to decide what to show you. For example, if you place an item in your shopping cart, a cookie could keep track of that info. If you log in to an account on a forum, a cookie keeps track of this as you navigate the pages.After a while, companies realized that they could use cookies in more invasive ways: to track you. By placing cookies on your computer, they can leave themselves notes about who you are and what you like. Then when you come back, they can use these notes to personalize the page and save more data about what you do online.

You might ask: why would I store a cookie like that on my computer? Why should my own software store this invasive tracking data about me and communicate it to tracking companies? My answer is: I don't know why you would do that. (Companies say it gives you a better experience). And if you choose not to, I'll discuss some ways to control this below.
Javascript.
In pursuit of continued interaction, the next step was the use of interactive programs running inside a webpage. When you send a request, the page delivers you the text, inline images, and also (perhaps) some "scripts" or programs that the page requests your browser to run. These scripts can be as small as mini animations or as complicated as an entire word editor (like Google Docs).Modern javascript is used for many purposes: interactive applications, more control over look and behavior, and information collection. For example, rather than serving text with styling commands, many pages will serve programs that dynamically load text and place it depending on your scrolling or other behavior. But as we'll discuss, javascript programs you run on your computer can potential do much more.
Although browser permissions should prevent javascript code you run from reading your files, it can collect information used to implicitly identify you or link your current browsing to other instances. Attributes such as height and width of your browser window, version of the browser, operating system, extensions in use, and more can combine to make you relatively unique (even if your IP address is not known or changes). This is called browser fingerprinting. Another example is tracking your mouse movements and keypresses and using them to attempt to identify you later on other sites.[18]
Finally, many websites contain javascript code that actively tries to hack, cheat, or exploit you. This code may delivered by any number of nefarious sites or ad networks (see below), so it can land on even seemingly-trustworthy pages. A recent example is javascript code that runs on your computer to mine bitcoins for someone else; this has popped up on sites like CBS Showtime.[19] A more worrying example is code that exploits flaws in your hardware multiprocessing (most famously the Spectre and Meltdown attacks[20]) to try to read passwords or sensitive data stored or entered elsewhere on your computer.
In summary, a "modern" webpage is a collection of components. These include the basic text and images; cookies used to save login information and identify you; and javascript programs that might do just about anything. Javascript is often used to create interactive experiences but has extreme potential for and history of abuse. These components are often loaded from many sources, not just the original site. If javascript is running, it can also connect to more places and load and run more code, etc. We'll see an example next.
News sites: a case study
Let's take another case study break. The following is typical of many sites on the web, but especially large news sites and some blogging platforms.
When Alice connects to her favorite news site (if any), it sends her back a relatively large HTML page that contains a variety of javascript programs. If she has enabled javascript in her browser, these begin running on her computer. Some of them load additional text and place text, video, etc. on the page. Many of them however are loaded from other places on the web.
In particular, often this javascript connects to a third-party advertisement company such as DoubleClick (which is associated with Google). It communicates Alice's cookies to that company, which uses an auction or some other mechanism to determine what ads to send back to Alice. For example, if Alice has recently searched for "shoes" on Google, it may have placed a cookie to that effect on Alice's computer. Or if Alice is currently logged into her Google account, she will have a cookie for that and Google may look deeper at her browsing history or other information it has on Alice in an effort to determine which ads to place. A similar example is the Facebook like button on many pages; it means that Facebook is receiving information that you visited the page (note Facebook attempts to track you regardless of whether you have a profile or are logged in[21]).
In my experience, typical news sites will load and run (if allowed) from fifty to over 100 different javascript programs and place at least a dozen cookies. They may connect to and run javascript code from 10-20 or so other companies, generally sending these companies information about your visit to the page. These companies are either involved in placing advertisements on the page or collecting data on your interests for later advertising.
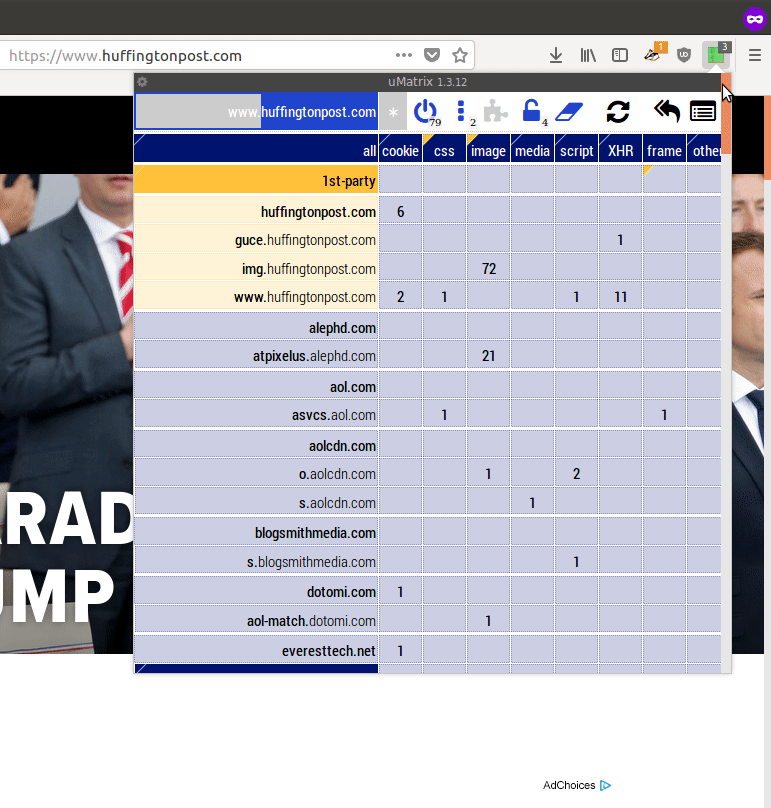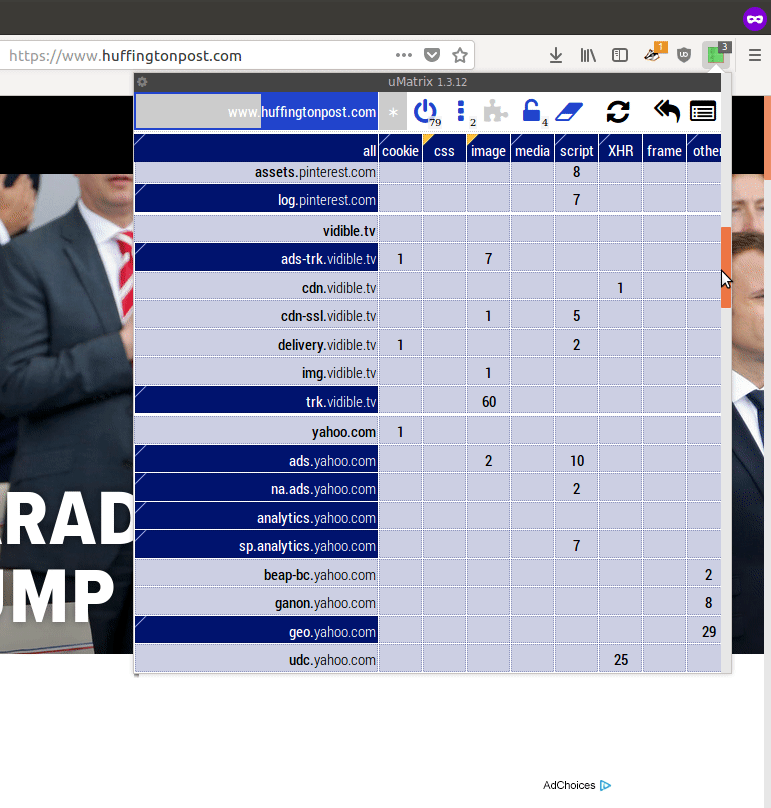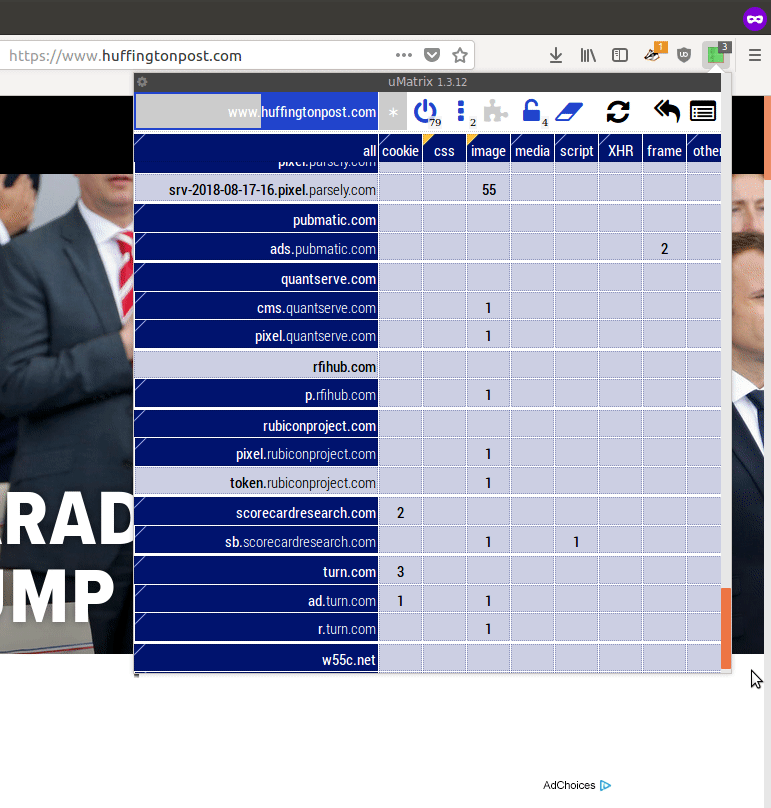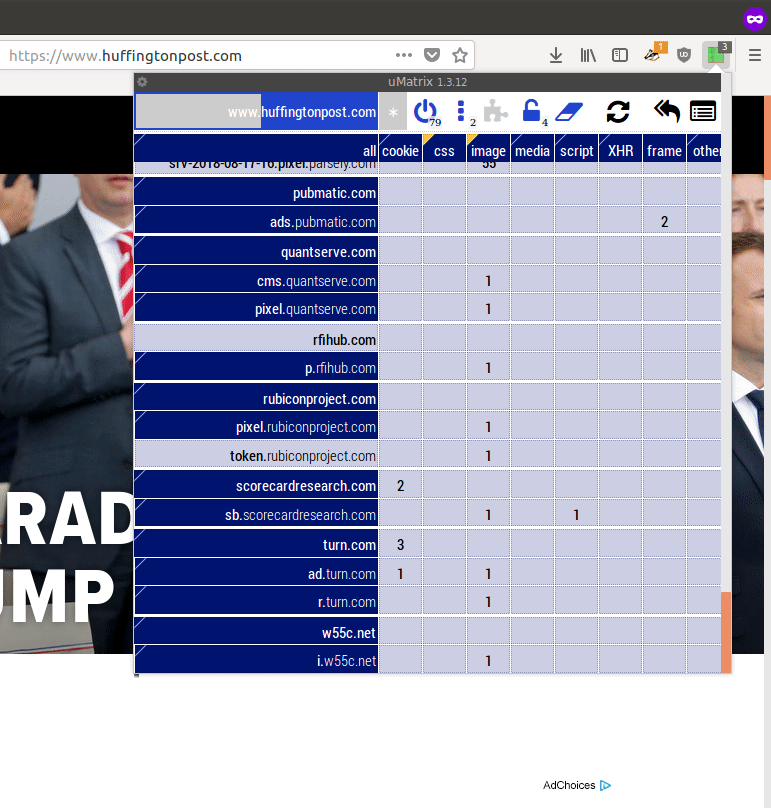
The extension uMatrix on a typical popular news site. (To see a GIF of scrolling this list down, click the image.) Across the top are the kinds of resources the page is using, especially cookies (far left) and javascript programs (toward the middle). Down the left side are all the various domains your computer is connecting to and sending information while loading the page, and what they are doing. Light yellow at the top is the "first party" website's own domains; all others are third party. Dark blue are sites tagged by uMatrix as being primarily advertising or tracking oriented.
Controlling your information
I hope the post so far has illustrated some choices you can make in regard to the hardware, operating systems, and software you choose. Here is some more detail and approaches if you would like more control over your information.
Browser settings and extensions.
The most common and egregious way that information is collected about us is probably via web browsing. We saw that two of the biggest transmitters of information are cookies and javascript. Luckily, browsers generally have settings that can block sites from setting cookies, and block your computer from running javascript without your permission. You can also clear your cookies regularly.Unfortunately, cookies and javascript both (a) have good use cases and (b) are often required by websites to function, even for bad reasons. To allow them where necessary, browsers often allow you to "whitelist" sites, meaning to add them to your personal list of approved sites that may set cookies; the same for javascript.
A more effective and less hands-on approach can be browser plugins or extensions that modify the behavior of your web browser. An example whose goal is purely to protect privacy is the Electronic Frontier Foundation's Privacy Badger plugin. There are also "adblockers" such as uBlock Origin that maintain blacklists of known tracking and advertising domains. These will allow most of a page to load, but block cookies and refuse to run javascript served from sites that only exist for tracking, browser fingerprinting, and such malicious purposes. They also block ads. Unfortunately, advertisements often come bundled with the above tracking behavior, so it is not generally possible to separate blocking of trackers and ads.

The Privacy Badger logo.
Other browser plugins include javascript blockers and the previously-pictured uMatrix, which allows you to set site-by-site permissions for different kinds of page resources. For instance, one can by default block all javascript and cookies, then ask the plugin to allow them for certain sites where one needs to log in or use a javascript application.
IP addresses.
Even if you block javascript and cookies, webpages still always have access to your IP address -- they need it in order to send data to you. But there are ways to hide your true IP from webpages you visit, by using "proxies". One is to use the Tor Browser, which also automatically protects against fingerprinting techniques. Tor works by routing your traffic through a network of computers worldwide, then sending it to the final destination webpage. The webpage sends data back to the most recent computer on the route, which then routes it through the network back to you. The page doesn't learn your IP address. (And remember that if you use https, your data is safe from being seen or modified by any of the computers in the network: best of both worlds!)
In addition to protecting everyday users' privacy, Tor protects political activists and circumvents censorship.
A similar approach is to use a Virtual Private Network (VPN). This is like Tor described above, but with just one "hop". Your phone or computer sends all its web traffic to some computer maintained by the VPN company, which then forwards it to websites. The websites see the IP address of the VPN server, not your computer. Unlike Tor, VPNs are generally a paid service. (If it's free, it's probably sketchy; even if paid, it might be sketchy.)
Both Tor and VPN have the added privacy bonus that many other users send their requests through the same endpoint. So fingerprinting or tracking your usage over multiple sites becomes much more difficult, as that same IP address is browsing many sites simultaneously. (Of course, if you have cookies set that a site can read and interpret, this is all pointless, so be aware of this if browsing over Tor or a VPN while logged in to an account.)
With both Tor and a VPN, an important additional privacy feature is that your ISP or phone company no longer collects information on what sites you visit. From the perspective of the ISP, all of your data is encrypted and goes straight to one computer (the VPN server or first hop of the Tor network). This also routes around any censorship of the ISPs or possibly government: since they can't see what sites you're trying to access, they can't block them. This is why Tor and VPNs are generally banned in China. Use of a VPN can also prevent ISPs from messing with your connection in other ways, e.g. throttling traffic.
Unfortunately, since Tor and VPNs are used for anonymity by malicious traffic as well, many sites will either block IP addresses they use, or require visitors to e.g. fill out CAPTCHAs. VPNs can also be used to route around region-specific censorship, and are often blocked for this reason. For example, Netflix blocks VPN traffic because a user in the USA could connect via a VPN in Australia, and with that Australian IP address, access Netflix content that is supposed to only be available to Australians.
Sandboxing.
It's also good to know about the concept of sandboxing. The term comes from giving programs a space they can play around in without hurting anything, isolated from fragile or sensitive stuff outside. Each browser acts as a sandbox for webpages and the code they run. They hopefully prevent those pages from doing things like reading your tax files or installing surveillance software, unless you explicitly agree by e.g. downloading and running an untrusted program (don't do that).Using a separate browser for different websites "sandboxes" them away from each other. It ensures they don't share cookies and may prevent fingerprinting from identifying you as the same person who browsed both sites. For example, you might log into an email or social media account on Browser A but browse the news or shop with Browser B. But if both browsers have the same IP address, this may be of limited success; I'm not sure. Some browsers are beginning to support this kind of sandboxing within the same browser.
But browser sandboxing is not perfect. In terms of javascript, recent attacks have shown ways that webpages can exploit "advanced" CPU features to e.g. detect passwords typed into other pages (see Spectre/Meltdown above). Javascript also allows much more sophisticated fingerprinting. Safer than sandboxing is not to let untrusted code run at all.
A more extreme form of sandboxing is to run a virtual machine. This is a "computer in a computer", an entirely different operating system running in a window. For example, you could run a version of Linux in a virtual machine and browse the web from Firefox in that VM. You can also make the IP address different as well, e.g. by connecting that virtual machine to a VPN in a different location.
The most extreme sandboxing, I suppose, is to use an entirely different physical device, e.g. a laptop used only for email and using email nowhere else, so it can't be leaked.
A final related technique is to use firewalls to block all Internet traffic to or from certain sites, such as known tracker networks. After setting up this firewall on a computer or home router, webpages or "smart" devices will be prevented from connecting to these sites. One can also set up VPNs at a home router level to ensure all traffic is routed through the VPN.
Wrapping up
Can I get just a little philosophical?
The vision of personal computing is to empower people to access information, entertainment, social connections, and more. Increasingly, computation is embedded into many aspects of our lives via devices we own and use. We nominally "own" these devices, but they follow instructions from many sources, not all aimed at empowering us.
One definition of ownership is: power of (exclusive) control. For many of us, the software we run on "our" devices is designed and controlled by companies, many of which we've never heard of and don't trust. It is used to collect information about us, and that information is ultimately used to influence our decisions: to exert control over our actions. So far, this data and control has been exercised in only a few ways, mostly advertising to influence our purchasing decisions, and influencing our political votes.
But these are your devices, which means this is ultimately up to you. I hope it's clear this post isn't trying to tell you what to do about your data. It's about understanding the process and how you can exercise control, if you so choose.

"My eyes are open."
So based on what we now know about how our information is collected, let's end by listing some of the techniques we can use with our devices and software to control the process.
- (Web browsing) Sandbox websites that use cookies. For example, you could use one browser only for social media, email, and such accounts, and a second for regular web browsing. Open all links in the second browser only and don't allow it to set cookies.
- (Web browsing) Consider using the Tor Browser for regular web browsing (not while logged into any account).
- (Web browsing) Install privacy-protecting browser extensions such as PrivacyBadger or "adblockers". (Be aware that malicious browser extensions can collect data about you too!)
- (Web browsing) Avoid running javascript except on sites you trust or where it is necessary (consider avoiding sites that require javascript if you can).
- (Web browsing) Subscribe to a VPN service and use it for daily web browsing.
- (All) Use a firewall or other service, either on your devices or in your home router level for home internet to prevent any data going to or coming from blacklisted sites.
- (Mobile, desktop/laptop) Avoid installing programs or apps that you don't trust. Avoid giving them permissions to access location data, microphone and camera, etc.
- (Other) Avoid purchasing "smart" or Internet-connected devices, especially without knowing what data they collect and send. Turn off or physically disable their Internet capabilities.
- (Mobile) Avoid carrying a phone, or leave your phone off most of the time. Or, accept that your realtime location data is likely for sale.
- (All) Consider preferring free and open source software, which by design has publicly auditable source code, tends not to be produced or controlled by for-profit or data-collecting companies, and has a primary purpose of serving the user not exploiting her.
Thanks for reading and hope it helps!
Notes:
[1] We'll skip many tangential issues. There's security: being hacked is one way to compromise privacy. There's also voluntarily giving up information, e.g. using a credit card reveals your location, time, and shopping habits; giving social networks your pictures helps them learn to identify your face; and any company you give personal info may leak it to firms like Cambridge Analytica. Etc.
[2] Just a few examples: News, Blog, stackexchange.
[3] Example sources: blocking sites (UK), throttling peer-to-peer, throttling Netflix.
[4] https://gizmodo.com/congress-just-gave-internet-providers-the-green-light-t-1793698939
[5] See this blog post for more.
[6] I am referring to the Intel Management Engine and AMD Secure Technology (PSP). For more, see e.g. this blog post.
[8] https://krebsonsecurity.com/2018/05/tracking-firm-locationsmart-leaked-location-data-for-customers-of-all-major-u-s-mobile-carriers-in-real-time-via-its-web-site/
[9] Source e.g. https://www.digitaltrends.com/cars/tesla-constant-cellular-tests-autonomy/
[10] https://www.popularmechanics.com/cars/how-to/a7469/your-car-is-spying-on-you-but-whom-is-it-spying-for/
[11] https://en.wikipedia.org/wiki/Smart_meter#Privacy_concerns
[12] e.g. https://www.wired.com/2017/02/smart-tv-spying-vizio-settlement/
[13] e.g. http://www.dailymail.co.uk/sciencetech/article-2950081/It-s-not-just-smart-TVs-home-gadgets-spy-internet-giants-collecting-personal-data-high-tech-devices.html
[14] I want to mention at this point that there are mathematical techniques, known as differential privacy, that allow some amount of data to be collected while mathematically guaranteeing some level of privacy. The idea is to add "noise" to your data so that it is not clear which sites you personally accessed, but when aggregating lots of people's responses, the noise washes out and statistics are useful. This is used by some browsers these days, but the effects on long-term privacy aren't yet clear.
[15] https://en.wikipedia.org/wiki/Superfish
[16] https://www.nytimes.com/2017/12/28/business/media/alphonso-app-tracking.html?_r=1.
[17] As far as I can tell. e.g. https://www.snopes.com/news/2016/06/04/professor-claims-facebook-is-eavesdropping-on-their-users/
[18] Banks are doing it for fraud detection, but others are also doing it for more nefarious purposes.
[19] https://www.theregister.co.uk/2017/09/25/showtime_hit_with_coinmining_script/
[20] https://meltdownattack.com/
[21] Source e.g. https://www.businessinsider.com/facebook-tracks-both-non-users-and-logged-out-users-2018-4/